A few years ago I took some statistics and R courses, and I noticed a peculiar thing: Every one of the instructors across the different training platforms started their analyses with a box plot. They did it to get a lay of the land and quickly spot potential issues like skew, kurtosis, and pesky outliers. That’s when my love affair with box plots began. After watching this video I’m confident yours will also be secured.
Become a Data Vis Wiz
You can order your copy of Making Data Sexy for PC or Mac from Amazon.
Video Transcript
Note: If you’re not Google, you will probably get very little from this transcript!
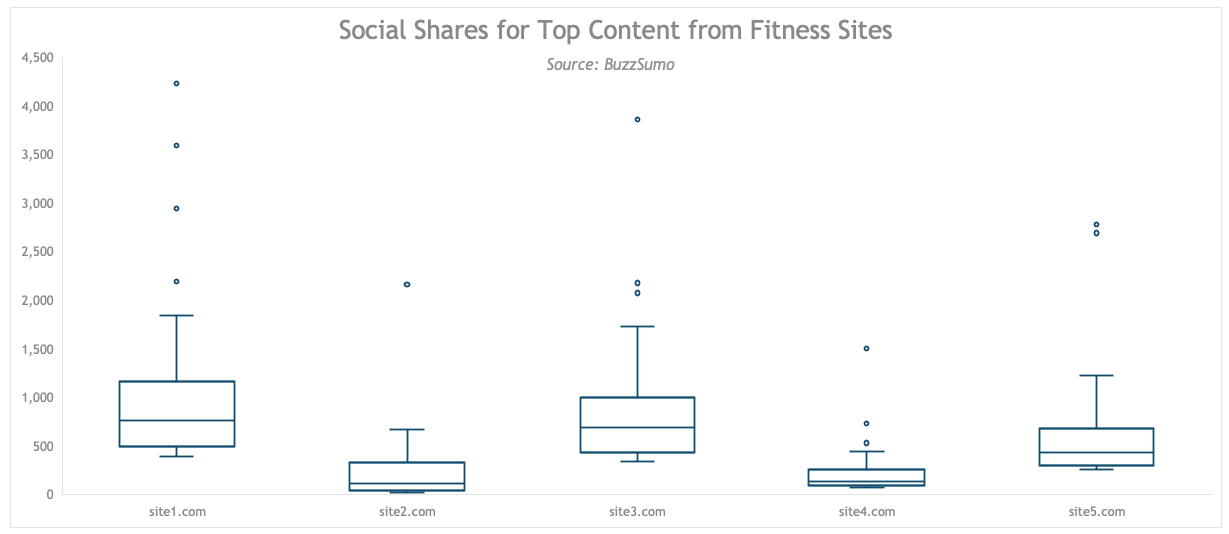
ok today we’re gonna talk about box plots I took some courses to learn are a couple years ago this is before I started working on my making data sexy book one thing that really stood out to me is that all of the instructors and this was across multiple courses without exception started their analyses with a boxplot and being a marketer I really wasn’t accustomed to using box plots that much I really thought of box plots as being more something for statisticians but I really came to love them and appreciate them watching these different instructors use them and so what I noticed that they would do is anytime they started with a new dataset they’d say okay well we’re just gonna throw this into a box plot in R which is really easy to do in R and they would just get kind of a lay of the land see how the data was distributed especially if they had multiple categories that they were looking at it also brought to light if there were any outliers which you can see just even looking at this box plot here these are all outliers which we’ll get into more so what I did was I took five popular fitness sites because I’m into fitness and I pulled their 100 top performing posts on social media for the month of December this was 2017 I was just starting to write the books and I put them in buzzsumo which is one of my favorite marketing tools hands down and I plotted the total shares for each of those landing pages then what I did was I just collected all five of them into one data set and then put them in this box plot so a few things I’ll point out just from the start one I anonymize the data you can tell that by site one site to site three etc I wasn’t exactly sure how these websites would feel about their data being publicly displayed in a book and discretion is a better part of our so also we won’t actually pull the URLs into the data set will be plotting they were of course included in the export from buzzsumo but we don’t actually need them in a box plot because with a box plot we’re looking at more distributions especially in this case across categories so we won’t need the specific URLs however you still need the URLs or whatever it is that you’re pulling from your export to give us the 100 line items for each of the website so they’re still in there we wouldn’t want to aggregate them because we need a hundred data points for each of these websites where that’s the number that I chose okay also the raw data didn’t actually include the sites so I added those in so with each export what I would do is I created this site column and then with the first export I just wrote site 1 and then copied it down the column and I’ll demonstrate how i did that with site 5 i’ll just type in site five.com enter and then i’ll go in here and I’ll just double click on this bottom right hand corner to send it down the rest of the column this will stop as soon as it hits a blank contiguous sub so once we have that now we’re ready to plot our data now all we’ll need I don’t know why we have these unsightly spaces here so what we’ll need to do to get started is select site and then press command shift down arrow control shift down arrow if you’re on a PC I’m on a Mac and we’re gonna go back up to the top with the first column still selected I am going to hold down the command key again control key if you’re on a PC and I’m gonna select this heading and then I’m gonna hold down the shift key and hit the down arrow again now I’ve selected two non-contiguous which means non-touching columns then we can come up into insert this is I think it says statistical charts yes statistical and then box-and-whisker really out in the wild these are just called box plots so let’s see on the PC you’ll go to insert charts insert statistic chart box and whisker I really wish the product managers for PC and Mac would get together and sync up their user interfaces personally I wouldn’t have had to write two books if they had okay so I’m just going to cut that and I’m gonna paste it into this sheet here and give ourselves room to work okay so first thing I’m going to do here is delete these gridlines we really don’t need them for this chart you can see by these little blue dots here I have them selected and I can just press backspace or delete we really don’t need them because with a boxplot this is really as I mentioned before we’re really looking at patterns and overall distributions so the gridlines don’t really help with anything now to pull up the formatting options normally with most things in Excel whether you select a chart or or a shape or text cell a table whatever you choose if you press command 1 or control 1 on a PC it will pull up a formatting pane sometimes it still pulls up a pop-up window excel has been on a mission to get rid of those which I applaud however for some reason with the charts that were new to 2016 command or control 1 doesn’t work so you actually have to right-click on any one of the charts and choose format data series as you see over here this will open up the format data series paint now if I choose my selection you’ll notice that this formatting pane will update to whatever I’ve selected which is kind of nice but we’re gonna go back to the data series the first thing I’m going to do is remove this fill this Phil is obfuscating some really important data points here so I’m going to choose this fill in line tab here and choose no fill and also I’m going to well no we have we have the main markers so that’s fine if you want to learn how to really go deep into formatting a boxplot so that it ends up looking super sexy like this get the book making data sexy calm you can learn all about it we’re not going to go deep into all the formatting options because in this video I really want to kind of evangelize the cause of box plots because they’re really really powerful they’re not the sexiest chart at all that I cover in the book but they are definitely one of the most powerful I would say in the top three and are probably my number one favorite since taking those courses so now that we have just some basic formatting options taken care of how do you actually read a box plot so I’m actually going to pull up this diagram that I created for the book and we’re just going to go through this because that’s really really important stuff so starting with the the min here the min is the smallest value in the data set outliers accept it and we’ll talk more about outliers in a minute for q1 25% of the data points fall below this point for q3 75% of the data points fall below that point the max is the largest number in your data set once again outliers accepted let’s skate on back down here to the median so the median is used a lot with box plots and it gets center stage over mean even though as marketers we really have a strong gravitational pull toward mean and mean is just geek speek for an average we really really love using average as our main measure of central tendency that’s what statisticians call it but in this case median is a really really good one the difference between mean and median is imagine with with median taking all of the numbers in your data set ordering them from smallest to largest and then picking the center number in that data set so if you had 99 data points I think that the middle number would be 50 I think don’t quote me on that if you had two numbers in the middle then you would take the average of those two numbers so if you had 10 and 14 is your two middle points then your median would be 12 so the box is a representation of the interquartile range or IQR and this really measures the spread of the data in your data set this is derived by subtracting the q1 value from q3 so that’s what gives you the box here and then these here these little lines here are called your whiskers and they extend from q1 to the minimum value and q3 to the maximum value now most programs like our and tableau give you the option to get rid of these little feet here most of the time the cool kids do not use them Excel doesn’t give you the option to get rid of them not that I could find so you conclude from that what you will okay so what constitutes an outlier you have to do a little bit of math here so if you take your IQR value so q3 minus q1 that value there and you multiply it by 1.5 and then you take that number and subtract it from q1 you’ll get your low outliers down here if you add it take that value and add it to q3 that’s what gives you these outliers up here and sometimes box plots are oriented horizontally so obviously the max values would be to the right the min values would be to the left and the outliers accordingly so going back to our chart here what can we conclude from this chart well a few things first of all we can see the site 1 has received the most social shares on average as evidenced by the position of its mean marker compared to the other sites oh and let me point out these here are your mean markers and one thing I do want to point out is that if the mean is above the medium then that data set has a positive skew if it’s positioned below the median then it has a negative skew so you can see in this chart all of these sites have a positive skew because the mean marker is above the medium and when I’m formatting box plots I will make all of these lines thicker you just select them you go in here you go to board or solid line and pump that up you just want to make them I just like making them bigger but again I’m not gonna go into all that I also make the mean marker bigger I make everything bigger more pronounced that aside so we can see here that site one definitely has had the most shares and if you hover over this X you’ll see that the value the mean or average was 1036 the closest to it was site 3 with 865 site 1 in site 3 also have a significant amount of deviation in the number of shares among their posts as evidenced by the spread of their boxes so you can see here these boxes are pretty tall so that indicates that there’s a spread in the data they’re not consistent they have some posts that get a lot more social shares and others that don’t and you can see they really have a significant amount of deviation in what is called the fourth quartile so this is the first quartile second third second and third quartiles make up the IQR and this is the fourth quartile so this is a really significant amount of spread site five also has a significant amount of deviation or spread in there fourth quartile so that to me indicates they had quite a few posts that they were right on the cusp of going viral and these outliers here I would say indicate posts that have gone viral they received a significantly greater number of social shares than the rest of the post now one thing to keep in mind with any kind of social including buzzsumo is that it’s a little bit off just because I think it was back in 2015 Twitter tickets count data and went home so if you look at the raw data again you’ll see the Twitter column is significantly under reporting so you can see Facebook shares versus Twitter shares obviously this is this is not accurate so if you have a site that’s much much stronger on Twitter than it is on Facebook their total social shares are really going to be distorted Thank You Twitter okay enough depressing news we can also see that site for although it receives a significantly lower number of shares they’re very consistent as is evidenced by their short box and site to is also very very consistent and since none of them have outliers on this low end none of them have completely bombed in terms of social shares so that’s good one other point I want to make is if you see a really significant gap between let’s say the mean and the median you really may want to consider relying more heavily on the median than the mean so let’s look at a practical example of this when I was working on the book this was April 2018 Walmart CEO Doug McMillon came under scrutiny for raking in twenty two point eight million dollars in earnings in the 2018 fiscal year the day that that story broke I noticed CNN’s headline read Walmart’s CEO earns one thousand one hundred and eighty eight times as much as company’s median worker so why didn’t CNN use the meat very simply because Macmillan salary ironically would have skewed the mean value pushing it higher so CNN used the median value similarly let’s say you’re a realtor reporting on average property values in Medina Washington well the gates and basis mansions will most likely significantly skew that data and negatively color your conclusions you definitely want to use median over me and for that reason real estate often uses median over mean values so although the boxplot isn’t your sexiest chart that’s at your disposal it’s a really good idea to throw your data into a box plot to get a lay of the land before turning to your favorite bar or line chart especially as marketers who are notorious for hiding the really interesting observations in Suns and averages you can learn more formatting tips to make these charts sexier in the book to learn more go to making data sexy calm